
おっと、前にJavaの配列について学んだよね!
配列って何?たくさんのデータをスッキリ整理整頓しよう! | ToolDocs
配列は同じ型のデータをまとめて扱える便利な機能だったけど、サイズが決まっちゃってるのが玉にキズだったね。データを追加したり削除したりするたびに、新しい配列を作り直してコピーして…って、ちょっと面倒くさかったんじゃないかな?
そこで今回は、もっと柔軟にデータを扱える「コレクションフレームワーク」について解説していくよ! これをマスターすれば、データ管理がグッと楽になること間違いなし!
コレクションフレームワークは、Javaが提供するデータ構造とアルゴリズムのセットなんだ。簡単に言うと、データを効率的に格納したり、検索したり、並べ替えたりするための「道具箱」みたいなものだと思ってくれてOK!
配列と違って、要素の数を気にすることなく、データを自由に追加したり削除したりできるのが最大のメリットだよ。
コレクションフレームワークの全体像
コレクションフレームワークは、たくさんのインターフェースとクラスで構成されているんだけど、最初は全部覚える必要はないよ。まずは、大きく分けて以下の3つのグループがあるってことを頭に入れておこう。
- List(リスト):データの「順番」を保ちたいときに使う。
- Set(セット):データの「重複」を許したくないときに使う。
- Map(マップ):データとデータを「ペア」で管理したいときに使う。
これらのインターフェースには、それぞれ色々な実装クラスがあるんだ。例えば、ListインターフェースにはArrayListやLinkedList、SetインターフェースにはHashSetやTreeSet、MapインターフェースにはHashMapやTreeMapなんかが代表的だね。
「なんのこっちゃ?」って思うかもしれないけど、具体的な例を見ていけばきっと理解できるはず!
Listを使ってみよう!
Listは、要素に順番があるのが特徴だよ。つまり、「1番目のデータ」「2番目のデータ」というように、追加した順番にデータが並ぶんだ。そして、同じデータを何度でも追加できるよ。
一番よく使われるのはArrayListかな。さっそく例を見てみよう!
Java
import java.util.ArrayList;
import java.util.List;
public class ListExample {
public static void main(String[] args) {
// 文字列を格納するArrayListを作成
List<String> fruits = new ArrayList<>();
// データを追加
fruits.add("りんご");
fruits.add("みかん");
fruits.add("バナナ");
fruits.add("りんご"); // 同じデータも追加できるよ!
System.out.println("--- 順番に表示 ---");
// データの取得(インデックスを指定)
System.out.println(fruits.get(0)); // りんご
System.out.println(fruits.get(1)); // みかん
System.out.println("--- 全て表示 ---");
// 全てのデータを順番に表示
for (String fruit : fruits) {
System.out.println(fruit);
}
// 要素数を取得
System.out.println("要素数: " + fruits.size()); // 4
// データの削除(インデックスを指定)
fruits.remove(0); // りんごを削除
System.out.println("--- りんご削除後 ---");
for (String fruit : fruits) {
System.out.println(fruit);
}
// データが含まれているかチェック
System.out.println("みかんは含まれている? " + fruits.contains("みかん")); // true
System.out.println("いちごは含まれている? " + fruits.contains("いちご")); // false
}
}
どう?配列と比べて、データの追加も削除も、めっちゃ簡単じゃない?add()で追加、remove()で削除、get()で取得って感じで、直感的に操作できるんだ。
ArrayListは内部的に配列を使っているんだけど、サイズがいっぱいになったら自動的に新しい配列を作り直してくれるから、開発者は配列のサイズを気にしなくていいんだ。これがコレクションフレームワークのありがたいところだね!
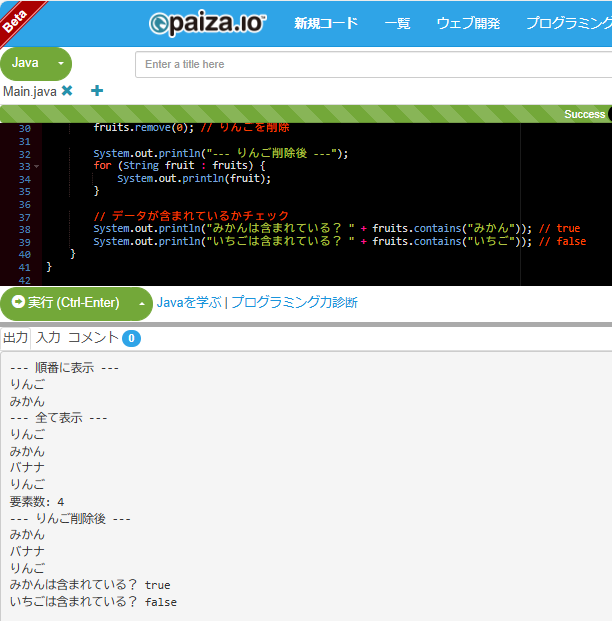
paizaで実行した結果
Setを使ってみよう!
Setは、データの重複を許さないのが最大の特徴だよ。同じデータを何度追加しようとしても、Setの中には1つしか存在しないんだ。また、Listのように要素の「順番」は保証されないよ。
よく使われるのはHashSetだね。これも例を見てみよう。
Java
import java.util.HashSet;
import java.util.Set;
public class SetExample {
public static void main(String[] args) {
// 文字列を格納するHashSetを作成
Set<String> colors = new HashSet<>();
// データを追加
colors.add("赤");
colors.add("青");
colors.add("黄");
colors.add("赤"); // 重複するデータは追加されない!
System.out.println("--- 色のセット ---");
// 全てのデータを表示(順番は保証されない)
for (String color : colors) {
System.out.println(color);
}
// 要素数を取得
System.out.println("要素数: " + colors.size()); // 3 (赤は1つだけ)
// データの削除
colors.remove("青");
System.out.println("--- 青削除後 ---");
for (String color : colors) {
System.out.println(color);
}
// データが含まれているかチェック
System.out.println("黄は含まれている? " + colors.contains("黄")); // true
System.out.println("緑は含まれている? " + colors.contains("緑")); // false
}
}
「赤」を2回追加しても、出力されるのは1回だけだよね。重複をなくしたい場合にSetはとっても便利だよ。例えば、ユーザーのIDリストとか、ユニークな値のリストを作るのに役立つね。
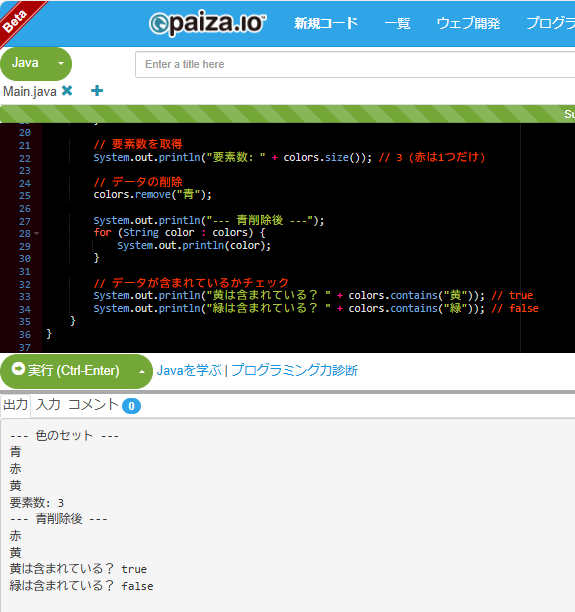
paizaで実行した結果
Mapを使ってみよう!
Mapは、キー(Key)と値(Value)をペアにして管理するデータ構造だよ。辞書をイメージすると分かりやすいかな。「りんご」というキーに対して「apple」という値、みたいな感じでデータを管理するんだ。キーは重複できないけど、値は重複してもOKだよ。
よく使われるのはHashMapだね。これも例を見てみよう!
Java
import java.util.HashMap;
import java.util.Map;
public class MapExample {
public static void main(String[] args) {
// キーがString、値がStringのHashMapを作成
Map<String, String> dictionary = new HashMap<>();
// データを追加 (putメソッド)
dictionary.put("apple", "りんご");
dictionary.put("banana", "バナナ");
dictionary.put("orange", "みかん");
dictionary.put("apple", "林檎"); // キーが重複すると値が上書きされる!
System.out.println("--- 英単語と日本語 ---");
// キーを指定して値を取得 (getメソッド)
System.out.println("appleの意味: " + dictionary.get("apple")); // 林檎 (上書きされた方)
System.out.println("bananaの意味: " + dictionary.get("banana")); // バナナ
// キーのセットを取得して全て表示
System.out.println("--- 全て表示 ---");
for (String key : dictionary.keySet()) {
System.out.println(key + ": " + dictionary.get(key));
}
// 要素数を取得
System.out.println("要素数: " + dictionary.size()); // 3
// データの削除
dictionary.remove("orange");
System.out.println("--- orange削除後 ---");
for (String key : dictionary.keySet()) {
System.out.println(key + ": " + dictionary.get(key));
}
// キーが含まれているかチェック
System.out.println("grapeは含まれている? " + dictionary.containsKey("grape")); // false
// 値が含まれているかチェック
System.out.println("バナナは含まれている? " + dictionary.containsValue("バナナ")); // true
}
}
put()でキーと値のペアを追加、get()でキーを指定して値を取得できるんだ。これは、IDとユーザー名、商品コードと商品名など、何かと何かを紐付けて管理したいときにすごく役立つよ!
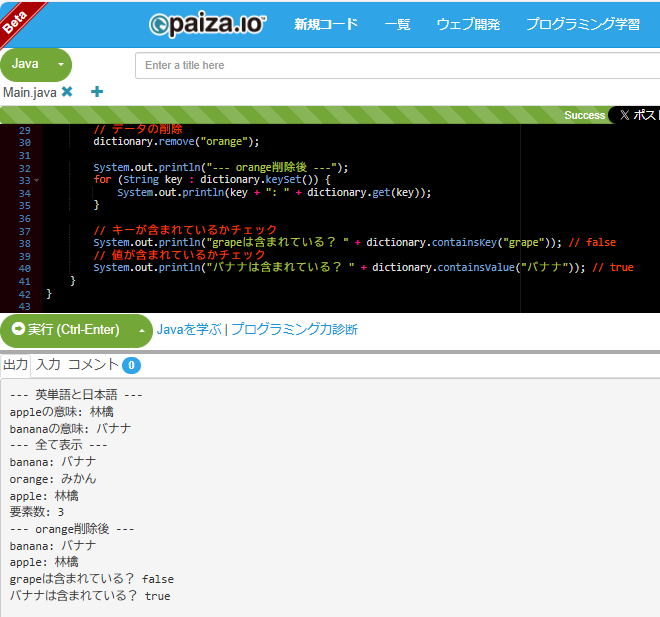
paizaで実行した結果
どのコレクションを選べばいいの?
これでList、Set、Mapの基本的な使い方は分かったと思うけど、じゃあ「いつどれを使えばいいの?」って疑問に思うよね。選び方のポイントは、それぞれの特徴を理解すること!
- 順番を気にしたい? -> List
- 追加した順番に並べたい、インデックスでアクセスしたいならこれ!
- 例: 買い物リスト、履歴、ログ
- 重複を許したくない? -> Set
- ユニークなデータだけを管理したいならこれ!
- 例: ユーザーIDの一覧、タグの集合
- キーと値のペアで管理したい? -> Map
- あるデータから別のデータを検索したいならこれ!
- 例: 辞書、電話帳、設定情報
最初のうちは、ListならArrayList、SetならHashSet、MapならHashMapを使っておけばOK! これらがそれぞれの代表的な実装クラスで、ほとんどの場面で困らないはずだよ。
まとめ
今回はJavaのコレクションフレームワークの全体像について解説したよ。
- コレクションフレームワークは、データを効率的に管理するための「道具箱」。
- 大きく分けて、List(順番あり、重複OK)、Set(順番なし、重複NG)、Map(キーと値のペア)の3種類がある。
- それぞれのインターフェースには、色々な実装クラスがあるけど、まずは
ArrayList、HashSet、HashMapを使ってみよう!
これらを使いこなせるようになれば、Javaでのデータ管理が格段に楽になるはず!
次回は、今回紹介しきれなかったコレクションフレームワークの便利な機能や、もっと詳細な使い分けについて掘り下げていくよ。お楽しみに!


コメント