
前回はJavaのイテレータについて学んだよね。
Javaイテレータ:コレクションの要素を順番に処理しよう! | ToolDocs
コレクションの要素を順番に取り出して処理する方法はバッチリかな? イテレータはとても便利だけど、もっと複雑なデータの処理、例えば「リストから特定の条件に合うものだけを選んで、別の形に変換して、最後に合計する」みたいなことをしようとすると、結構コードがごちゃごちゃしちゃうんだ。
そこで今回紹介するのが、Java 8から導入されたストリームAPIだよ! ストリームAPIを使うと、データの加工や集計がもっとスマートに、分かりやすく書けるようになるんだ。例えるなら、データの流れを「パイプライン」のように扱うイメージかな。
ストリームAPIってなに?
ストリームAPIは、コレクションなどの「データの源」から流れてくる要素に対して、様々な操作を連続的に行うための仕組みだよ。まるで工場で部品が流れてきて、それぞれの工程で加工されていくような感じ!
イテレータとの大きな違いは、イテレータが「一つずつ要素を取り出して手動で処理する」イメージなのに対して、ストリームは「データが自動的に流れて、決められた処理を順に適用していく」イメージなんだ。
ストリームAPIを使うメリットはたくさんあるよ。
- コードが簡潔になる: データの加工処理をチェーンのように繋げて書けるから、読みやすい!
- 並列処理が簡単: 大量のデータを高速に処理したいときに、簡単に並列処理に切り替えられる(これはちょっと応用だけどね)。
- 遅延評価: 必要になったときにだけ処理を実行するので、無駄な計算が少ない!
ストリームAPIの基本的な流れ
ストリームAPIを使った処理は、大きく分けて3つのステップで構成されるよ。
- ストリームの生成: データの源(コレクション、配列など)からストリームを作る。
- 中間操作: ストリームの要素を加工したり、フィルタリングしたりする。これらの操作は、新しいストリームを返すので、さらに次の操作を繋げられる(チェーン化できる)。
- 終端操作: ストリームの処理を実行し、結果を得る(リストにする、合計する、画面に表示するなど)。終端操作が呼ばれて初めて、中間操作が実行されるんだ。
さっそく、簡単な例を見てみよう!
Java
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors; // collectメソッドを使うために必要
public class StreamBasicExample {
public static void main(String[] args) {
// データの源となるリスト
List<String> fruits = new ArrayList<>();
fruits.add("りんご");
fruits.add("みかん");
fruits.add("バナナ");
fruits.add("ぶどう");
fruits.add("いちご");
System.out.println("元のフルーツリスト: " + fruits);
// ストリームを使って「ん」で終わるフルーツをフィルタリングし、新しいリストに格納
List<String> filteredFruits = fruits.stream() // 1. ストリームの生成
.filter(fruit -> fruit.endsWith("ん")) // 2. 中間操作: 「ん」で終わるものだけ残す
.collect(Collectors.toList()); // 3. 終端操作: 結果をリストに集める
System.out.println("「ん」で終わるフルーツ: " + filteredFruits);
}
}
実行結果:
元のフルーツリスト: [りんご, みかん, バナナ, ぶどう, いちご]
「ん」で終わるフルーツ: [りんご, みかん]
どうかな? fruits.stream() でストリームを作って、filter() で条件に合うものだけを選び、collect() で結果をリストにまとめているよね。たったこれだけで、イテレータで書くよりもずっとスッキリ書けるんだ!
filter(fruit -> fruit.endsWith("ん")) の fruit -> fruit.endsWith("ん") の部分は、「ラムダ式」っていう便利な書き方だよ。これは「fruit という引数を受け取って、fruit.endsWith("ん") の結果を返す」っていう処理を意味しているんだ。最初はちょっと戸惑うかもしれないけど、慣れるとすごく便利だよ!
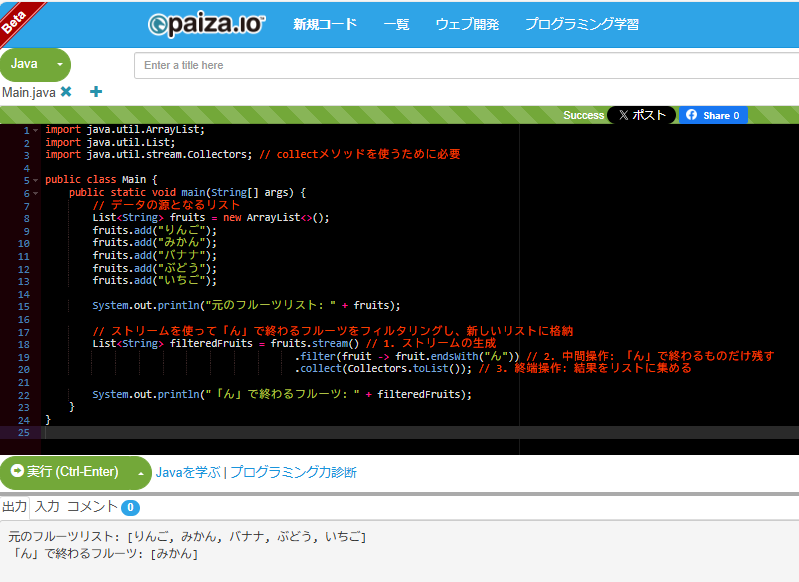
paizaで実行した結果
よく使う中間操作を見てみよう!
ストリームAPIには、たくさんの便利な中間操作があるんだ。いくつか代表的なものを紹介するね。
filter():条件に合うものだけ残す
さっきも使ったけど、これが一番よく使う操作の一つだね。
Java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamFilterExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 偶数だけを抽出する
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0) // nを2で割った余りが0(偶数)のものだけ
.collect(Collectors.toList());
System.out.println("偶数: " + evenNumbers); // [2, 4, 6, 8, 10]
}
}
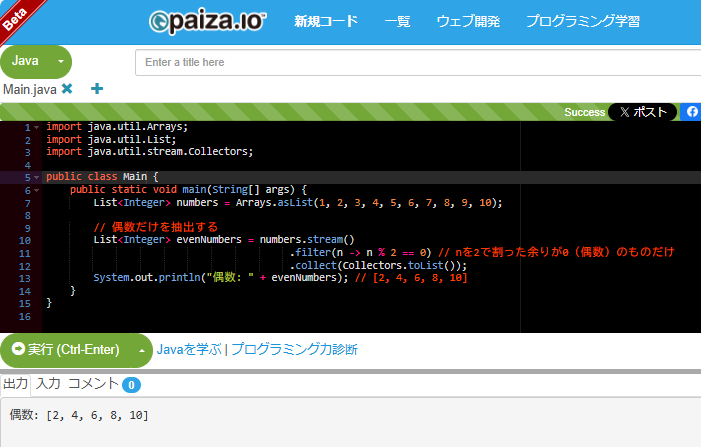
paizaで実行した結果
map():要素を別の形に変換する
ストリームの各要素に何らかの加工を加えて、新しい要素のストリームを作るよ。
Java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamMapExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
// 各名前を大文字に変換する
List<String> upperCaseNames = names.stream()
.map(name -> name.toUpperCase()) // 各nameを大文字に変換
.collect(Collectors.toList());
System.out.println("大文字の名前: " + upperCaseNames); // [ALICE, BOB, CHARLIE]
// 各数値に10を掛ける
List<Integer> numbers = Arrays.asList(1, 2, 3);
List<Integer> multipliedNumbers = numbers.stream()
.map(n -> n * 10) // 各nに10を掛ける
.collect(Collectors.toList());
System.out.println("10倍された数値: " + multipliedNumbers); // [10, 20, 30]
}
}
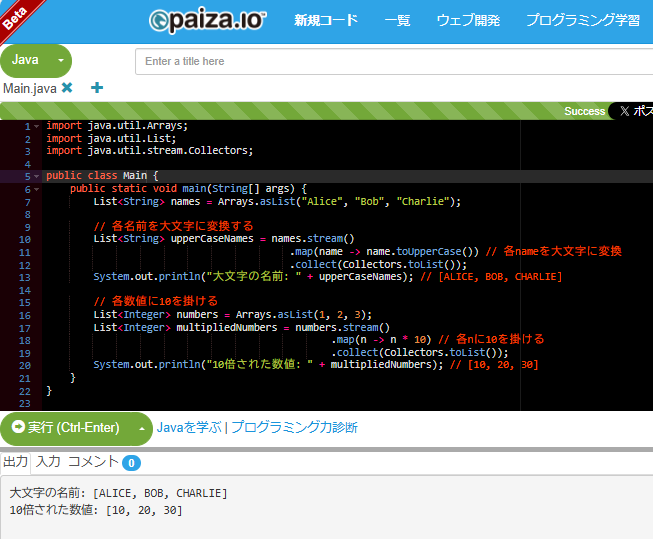
paizaで実行した結果
sorted():要素を並び替える
ストリームの要素を自然順序、または指定した順序でソートするよ。
Java
import java.util.Arrays;
import java.util.Comparator; // 逆順にする場合に必要
import java.util.List;
import java.util.stream.Collectors;
public class StreamSortedExample {
public static void main(String[] args) {
List<String> words = Arrays.asList("apple", "orange", "banana", "grape");
// アルファベット順にソート
List<String> sortedWords = words.stream()
.sorted() // 自然順序(アルファベット順)
.collect(Collectors.toList());
System.out.println("ソートされた単語: " + sortedWords); // [apple, banana, grape, orange]
// 文字列の長さでソート
List<String> sortedByLength = words.stream()
.sorted(Comparator.comparing(String::length)) // 長さでソート
.collect(Collectors.toList());
System.out.println("長さでソートされた単語: " + sortedByLength); // [apple, grape, banana, orange]
}
}
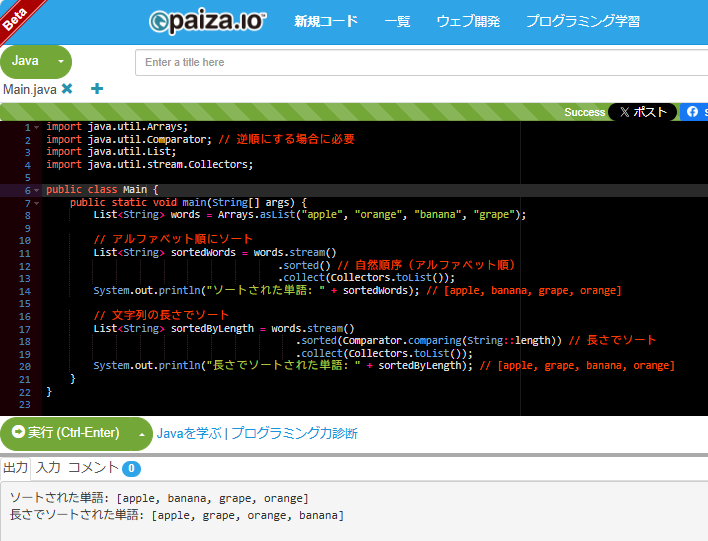
paizaで実行した結果
distinct():重複する要素を削除する
同じ要素が複数ある場合、重複を排除してユニークな要素だけを残すよ。
Java
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamDistinctExample {
public static void main(String[] args) {
List<Integer> numbersWithDuplicates = Arrays.asList(1, 2, 2, 3, 1, 4, 5, 4);
// 重複を除去
List<Integer> distinctNumbers = numbersWithDuplicates.stream()
.distinct()
.collect(Collectors.toList());
System.println("重複除去後の数値: " + distinctNumbers); // [1, 2, 3, 4, 5]
}
}
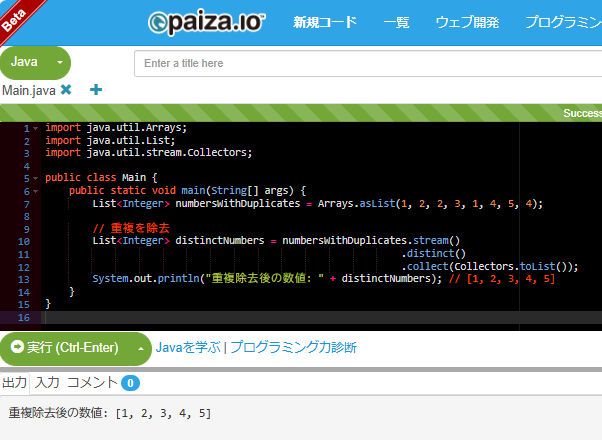
paizaで実行した結果
よく使う終端操作を見てみよう!
終端操作は、ストリームの処理を「実行」して、最終的な結果を得るためのものだよ。
forEach():各要素に対して処理を実行する
ストリームの各要素に対して、何らかの処理を行う場合に使うよ。
Java
import java.util.Arrays;
import java.util.List;
public class StreamForEachExample {
public static void main(String[] args) {
List<String> greetings = Arrays.asList("Hello", "Hi", "Good morning");
System.println("挨拶:");
greetings.stream()
.forEach(s -> System.out.println(s + "!")); // 各要素の後に「!」をつけて表示
}
}
実行結果:
挨拶:
Hello!
Hi!
Good morning!
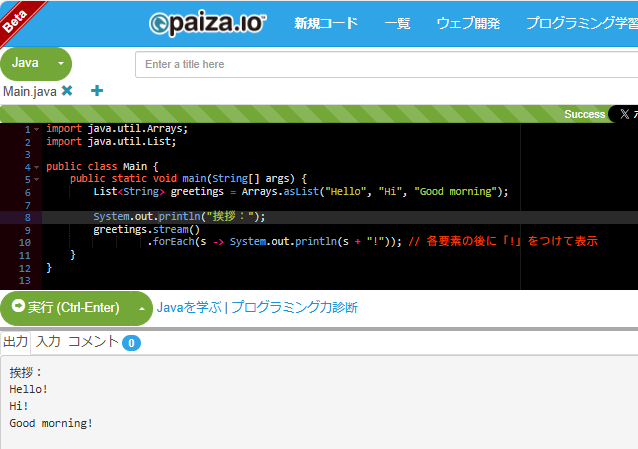
paizaで実行した結果
collect():結果をコレクションに集める
中間操作で加工されたストリームの要素を、新しいリストやセットなどにまとめる場合に使うんだ。これが一番よく使う終端操作かもね。
Java
import java.util.Arrays;
import java.util.List;
import java.util.Set; // Setに集める場合
import java.util.stream.Collectors;
public class StreamCollectExample {
public static void main(String[] args) {
List<String> words = Arrays.asList("apple", "banana", "orange", "apple");
// 重複を除去してSetに集める
Set<String> uniqueWords = words.stream()
.collect(Collectors.toSet());
System.out.println("ユニークな単語 (Set): " + uniqueWords); // [orange, apple, banana] (順序は保証されない)
// 長さが5以上の単語をリストに集める
List<String> longWords = words.stream()
.filter(s -> s.length() >= 5)
.collect(Collectors.toList());
System.out.println("長さ5以上の単語 (List): " + longWords); // [apple, banana, orange, apple]
}
}
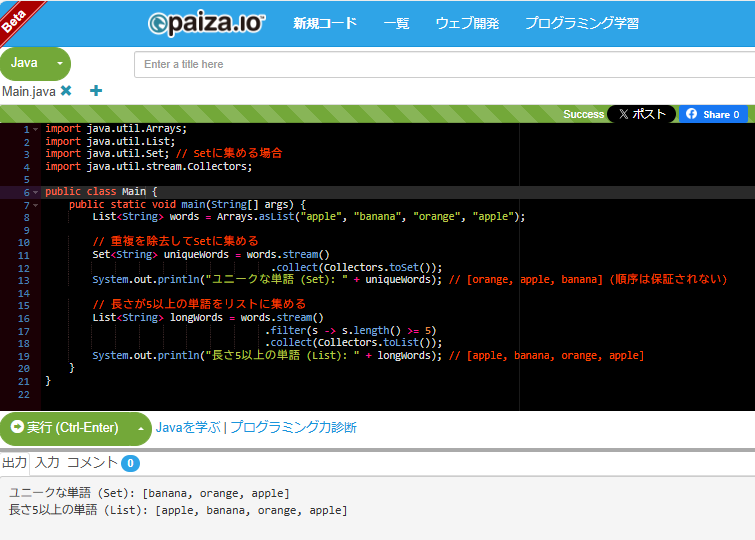
paizaで実行した結果
count():要素の数を数える
ストリームに含まれる要素の数を数える場合に使うよ。
Java
import java.util.Arrays;
import java.util.List;
public class StreamCountExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
// 3より大きい数値の数を数える
long count = numbers.stream()
.filter(n -> n > 3)
.count();
System.out.println("3より大きい数値の数: " + count); // 3 (4, 5, 6)
}
}
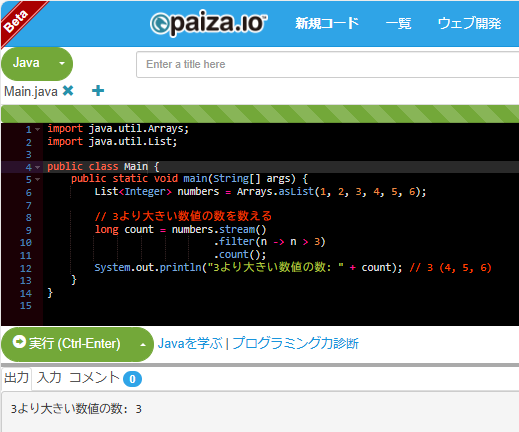
paizaで実行した結果
sum(), average(), min(), max() など:数値の集計
数値のストリームの場合、合計や平均、最小値、最大値などを簡単に計算できるんだ。ただし、これらの操作はIntStreamやLongStream、DoubleStreamといったプリミティブ型のストリームでしか直接使えないことが多いから注意が必要だよ。
Java
import java.util.Arrays;
import java.util.List;
import java.util.OptionalDouble; // averageの戻り値
public class StreamSummaryExample {
public static void main(String[] args) {
List<Integer> scores = Arrays.asList(70, 85, 90, 65, 95);
// 合計点
int totalScore = scores.stream()
.mapToInt(Integer::intValue) // IntStreamに変換
.sum();
System.out.println("合計点: " + totalScore); // 405
// 平均点
OptionalDouble averageScore = scores.stream()
.mapToInt(Integer::intValue)
.average();
averageScore.ifPresent(avg -> System.out.println("平均点: " + avg)); // 81.0 (OptionalDoubleなのでifPresentで取り出す)
// 最高点
int maxScore = scores.stream()
.mapToInt(Integer::intValue)
.max()
.orElse(0); // 値がない場合のデフォルト値
System.out.println("最高点: " + maxScore); // 95
}
}
mapToInt(Integer::intValue) のように、オブジェクトのストリームをプリミティブ型のストリームに変換することで、sum() や average() などが使えるようになるんだ。
paizaで実行した結果
まとめ
今回はJava 8から追加されたストリームAPIについて学んだよ。
- ストリームAPIは、データの流れをパイプラインのように処理するための仕組み。
- ストリームの生成 → 中間操作 → 終端操作 の3ステップで処理を行う。
- 中間操作(
filter(),map(),sorted(),distinct()など)は新しいストリームを返すので、チェーンのように繋げて書ける。 - 終端操作(
forEach(),collect(),count(),sum()など)はストリームの処理を実行し、最終的な結果を返す。 - イテレータに比べて、コードが簡潔で分かりやすく書けるのが大きなメリット。
ストリームAPIは最初は少し難しく感じるかもしれないけど、慣れてくるとJavaでのデータ処理が格段に楽になる強力なツールだよ! ぜひ色々な例を試して、使いこなせるようになってね!
前回の記事はこちらから → Javaイテレータ:コレクションの要素を順番に処理しよう! | ToolDocs


コメント